(by Francesca L. Bleken, Jesper Friis (both SINTEF Industry), Joh Dokler (Seven Past Nine d.o.o.), and Thomas E. Exner (Seven Past Nine GmbH)
Effective and efficient materials innovation following the Safe-and-Sustainable-by-Design approach, heavily relying on digital and computational approaches as proposed by the PINK projects, requires access to all relevant data and modelling for seamless integration into the decision-making process from ideation to registration and market introduction. Such resources must include descriptions of the full value chain and the materials’ life cycle and there. Therefore, one of the high-level objectives of PINK is to build an open infrastructure, i.e., an open innovation platform, which is designed to allow easy integration of PINK as well as third-party data and modelling resource and straightforward export of PINK tools into other platforms and infrastructures based on a well-documented, vendor agnostic and modular technical and semantic Interoperability Framework. In this way, these individual resources complemented by newly developed management tools can be seen as prototypes for the possible realisation of a European distributed and federated materials data/digital ecosystem as envisioned by the “Materials Commons” in the European Commission’s “Advanced Materials Industrial Leadership” strategy which is based on the Roadmap of the Advanced Materials 2030 Initiative (AMI2030).
Addressing the Interoperability Limitations through stand-alone Modules
The idea of integrable and interoperable data, models and software tools is not new. Many database systems and modelling platforms used in SSbD are designed to integrate data and modelling resources from different providers, multiple projects and/or complete communities and adapt them to the settings in the specific system at hand. However, due to these specific adaptations, cross-system or even cross-domain interoperability is still quite limited since (a) data and models are locked into technical silos, i.e. data and models from one platform can easily be combined to form integrated assessment workflows but not with individual data points or models implemented in another platform and (b) interoperability has to be based on full integration of one system into another or on customised pipelines accessing both systems and then performing data transformation to achieve interoperability.
PINK is following a different approach as outlined in Figure 1: Datasets and computational models, workflows and software are seen as individual digital objects, which exist independently from any modelling platform implementation. Based on PINK’s data documentation approaches, these digital objects are meant to become self-explanatory stand-alone modules thereby facilitating their integration into different systems and environments (i.e. user hubs). This stand-alone module encapsulates all necessary data documentation of a resource as triples (and is store in a triple store). This includes where to find it (findability), how to access it (accessibility), how to interpret it down to the numerical level with data models (interoperability) and how it is connected to other data (reusability). PINK defines a user hub as a user-facing application and interface, which is integrating different resources and provides additional functionality on top of these (see Table 1 for a working definition) and thus, databases, modelling platforms, knowledge graphs and decision support tools are all considered to belong in the group of user hubs since they provide human-machine interfaces into the SSbD digital ecosystem. The PINK In-Silico Hub (PINKISH) will combine many of the just mentioned functionalities and is thus the specific implementation of a user hub resulting from the PINK Project.
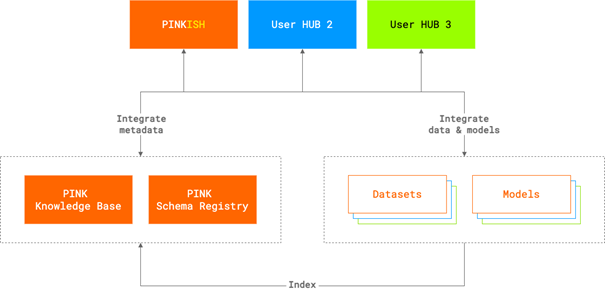
Figure 1: Schematic representation of the components of a digital infrastructure supporting PINK’s dual interoperability approach. Data and models are seen as individual digital objects. These are accompanied by detailed documentation and semantic annotation for human understandability- and increasingly computer-actionability. The documentation will provide information to be indexed in the PINK Knowledge Base (KB) to support findability and accessibility (the first two letters in FAIR) as well as the relationships between resources thereby supporting interoperability (the third letter in FAIR). Additionally, the data models with their documentation (which are used in the datasets and model inputs/outputs) will be stored in the PINK Schema Registry for inspection and reuse. The PINK infrastructure components will then facilitate the integration of the data, models and workflows based on these data models into user hubs such as the PINK In-Silico Hub (PINKISH).
The federated data management system is being developed so that access rights can be handled based on the individual resources keeping the full control in the hands of the data producer or model / software developer thereby facilitating, on a case-by-case basis, sharing of resources that are FAIR (Findable, Accessible, Interoperable and Reusable) but not necessarily fully open. The full global adoption of this distributed and federated approach can only be achieved through a community-wide, cross-sectional and cross-domain effort and PINK has initiated and is building upon many collaboration and networking activities to achieve the technical but even more importantly social and mental transition from classical databases and stand-alone modelling environments to individual and FAIR digital objects. PINK will provide crucial technical components like the PINK Knowledge Base and the PINK Schema Registry, which will make such a transition possible and are outlined in Table 1. If you are interested in the Interoperability Framework and the infrastructure components, please stay tuned on the PINK newsletters or contact us.
Table 1: Description of the components of the PINK infrastructure also forming the starting point for defining the PINK nomenclature. This includes services developed within the PINK project as well as existing and new resources provided by PINK partners and third parties.
| Component | Definition and purpose |
| Data resources | This includes (meta)data and knowledge resources, which provide information used in the SSbD process for supporting the design and multi-objective optimisation of advanced materials and chemicals, and especially the decision-making process when moving from one material development cycle to the next. This information can be stored in individual datasets or as project-internal (developed and/or integrated in WP2) or third-party (onboarding) data / knowledge bases and knowledge graphs. |
| This includes individual models, workflows combining multiple modelling techniques, as well as complete toolboxes and modelling platforms. As is the case for data resources, these model resources can come from PINK partners (developed and/or integrated in WP2) or third parties (onboarding). | |
| The Knowledge Base is a support service that will index all data and modelling services and provide relationships between them in the form of a knowledge graph based on the documentation provided by the data or model service developers. While working on the specifications for the PINK Platform (see below), it was recognised that all search, browse, access and integration support functionalities can be offered in one service resulting in integrating the PINK Registry (as it is described in the Description of Action) into the PINK KB. In this way, the KB will provide the main searching and browsing functionality to find appropriate data and model resources, recommendations on how to apply and combine them for their efficient and effective use at the earliest possible stage in the material or chemical development process, as well as access to additional (meta)data to evaluate the quality and confidence levels of predictions resulting from the model resources. | |
| PINK Schema Registry | This database is the second support service and will store the well-documented and highly annotated data schemas used to describe data resources (datamodels), as well as inputs, outputs and additional metadata of model resources. This will be necessary to allow inspection of existing data schemas by a user thus driving potential re-use for structuring new resources as PINK-compliant FAIR digital objects. |
| User hubs | User hubs are implementations of user-facing interfaces, which build advanced features integrating the underlying data and model resources. This includes many digital SSbD platforms developed e.g., in the different projects of the HORIZON-CL4-2023-RESILIENCE-01-23 call. When implementing the vision of Figure 1, where dataset and models are seen as individual digital objects existing independently from a specific implementation, databases can be considered as one version of such hubs since they give access to data resources and then add functionality for searching, browsing and visualising the data. Such a view shifts the role of a database from storing the data to supporting data integration, interpretation, enrichment and reuse. Modelling cloud platforms like Jaqpot and Enalos are another type of user hub and their functionality to develop and evaluate models and visualise results will be used in PINK. However, since these services will be used to implement, deploy and share models, they are seen more as model resources in the context of this Deliverable. Finally, knowledge graph approaches can also be regarded as user hubs as they rely on provision of information from the data and model resources and restructure them to provide new insights. The Integrated Knowledge Graph for Chemical Impact Assessment and the PINK KB will be two such applications, even if the latter is limited to the integration of metadata and not the actual data provided by the indexed resources. |
| PINKISH (PINK In-Silico Hub) | PINKISH is the specific implementation of a user hub developed by the PINK project to specifically address its objectives. It will build the computer-human interface by giving access to the data and model resources as well as to management and support services (user management and guidance) and will enable the innovative AI-enabled decision support (downstream) services. The latter includes the Material Dashboard, the Integrated Knowledge Graph for Chemical Impact Assessment, the Generative AI, and the Decision Support Workflow to be developed in WP4. While these downstream services will share implementation details with the model resources and might be implemented using platforms like Jaqpot, Enalos and ModelWave, their specifications will not be covered in this report since they will be based on the developments in WP4 and WP5 (and will be described in the Deliverable reports from these WPs), and optimised by addressing requirements and requests coming from the Developmental Case Studies of WP6. |
| PINK Platform | The PINK Platform is the combination of all infrastructure components described above into an open innovation platform (OIP), i.e., a digital platform facilitating, co-creation, collaboration and knowledge-sharing between different organisations or individuals. |